Subtitle Edit instructions
Subtitle Edit is a program that allows you to create, edit, and schedule subtitles for videos and transcribe audio or video. Particularly good features in Subtitle Edit are the precise adjustment options for how much and for how long the text appears on the screen at a time.
The program can create subtitles or transcription with automatic speech recognition. The program is suitable for automatic transcription of sensitive or confidential material, because it only runs on a local computer, and does not send anything to the network.
Installing Subtitle Edit
- For TUNI Windows computers install Subtitle Edit in the Software Center
- For other computers (Windows and Linux), the installation package can be downloaded from https://github.com/SubtitleEdit/subtitleedit/releases
Transcription or subtitles with speech recognition
Preparations
Processing personal data
- If you process personal data, you must always carry out a data protection risk assessment of the processing, see the pages Data protection in research – general instructions and Data Protection Impact Assessment (DPIA).
- If you process material belonging to special categories of personal data (Article 9 of the EU General Data Protection Regulation) or other data belonging to the data class 2A or 1R (see instructions at Data classification)
- The processing must be subject to a thorough data protection impact assessment (DPIA), see the page Data Protection Impact Assessment (DPIA) for instructions on how to do so.
- If a student needs to process special categories of personal data, the faculty must enter into an extended resource agreement for the student and request via it-helpdesk [at] tuni.fi (IT Helpdesk) a centrally managed computer (similar to that of the staff) for the student.
- Data may only be processed on a computer centrally maintained by IT Services, never on one's own home computer.
- The material and the transcript must be stored encrypted with a separate program. See the page Management and storage of research data for instructions.
- Speech recognition using the OpenAI Whisper based algorithms works on all Windows computers. However, it works much faster if the machine has a Nvidia graphics card with sufficient memory.
Speech recognition
- Open the video or audio recording by selecting Open video file in the Video menu (note the video/audio option at the bottom right).
- On the first run, download the program's proposed add-on mpv by clicking the button Download and use "mpv" as a video player.
- Select Audio to text (whisper) in the Video menu.
- On the first run, download the program's proposed add-ons FFmpeg and Purfviews Faster-Whisper.
- Let the Engine (speech recognition program) be the default (at the time of writing Purfview’s Faster-Whisper) because it has been checked to work.
- You can choose another engine, but it may be an unknown program for the Windows security mechanism AppLocker. In that case AppLocker will prevent the program from running and you will receive a notification about it. If that happens, send an email to IT Helpdesk telling: the name of your computer, that you used an engine, and you received the AppLocker notification in the Subtitle Edit program, and requesting in the message that AppLocker would allow that engine to run. You can take a screenshot of AppLocker's notification or otherwise write down the program mentioned in the notification, but IT Helpdesk can also find that information in AppLocker's logs.
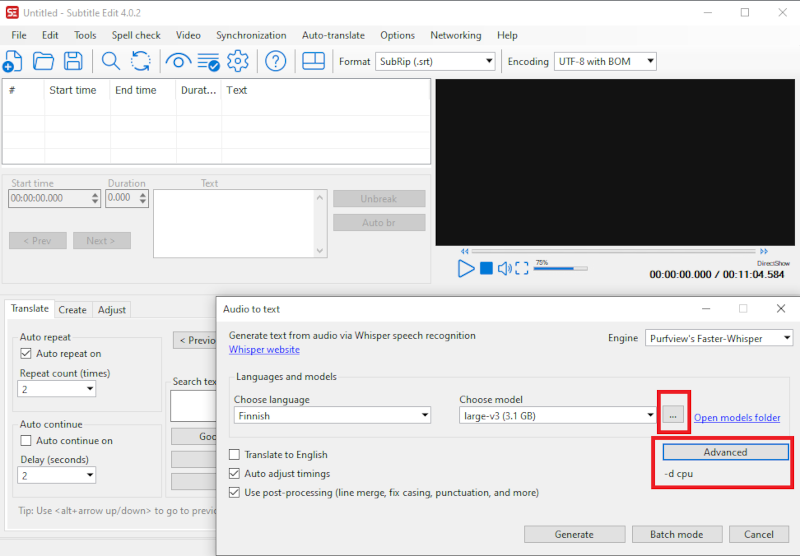
- In Choose language, select the language spoken in the recording.
- In Choose model three-point menu, select the language model you want to use for speech recognition.
- Templates without ".en" at the end of their name are multilingual.
- The bigger the language model, the better it recognizes speech, but the slower it is. Large-v3 is apparently currently the best. The detection takes about 3 times the duration of the recording on a basic TUNI computer. With Medium model, the detection takes about half of what with Large models. Try out which model best suits your needs.
- See the Whisper project page for more information on the models.
- The program loads the language model to be used on the first run. Later it can be found in the Choose model list. The largest language model is over 3 GB and it takes quite a long time to download.
- On the first run, download any add-ons suggested by the program (Cublas, cuDNN libs).
- Select Generate to start processing the recording.
- Speech recognition can fail if the computer has a separate graphics card with too little memory (Large models need 8 GB). In this case, specify "-d cpu" in Advanced, in which case speech recognition is done with the processor alone. That setting can also be good on a computer that doesn't have a separate graphics card, as it can speed up detection.
- You can put multiple recordings for processing in a row using the Batch function.
- After the transcription is produced with speech recognition, you can make corrections to the subtitle SRT file in the editor.
- In the File menu, select Export - Plain text to save the text. At the same time, you can choose text formatting, such as time codes and wrapping.
- See the developer's page for further instructions on how to use the program.
Below is an example where a Large-v3 language model and the computer processor are used for speech recognition.
IT Helpdesk
0294 520 500
it-helpdesk [at] tuni.fi (it-helpdesk[at]tuni[dot]fi)
helpdesk.tuni.fi
Published: 22.9.2022
Updated: 31.10.2025