Subtitle Edit -sovelluksen ohjeet
Tampereen yliopisto ja TAMK
Subtitle Edit on tekstitysohjelma, jolla voi luoda, muokata ja ajastaa tekstityksiä videoihin sekä litteroida audiota tai videota. Subtitle Edit -ohjelmassa erityisen hyviä ominaisuuksia ovat tarkat säätömahdollisuudet siihen, kuinka paljon ja kuinka kauan tekstiä näkyy ruudulla kerrallaan.
Ohjelmalla voi luoda tekstityksiä ja litteraatteja automaattisella puheentunnistuksella. Ohjelma sopii myös sensitiivisen tai luottamuksellisen aineiston litterointiin, koska se toimii vain paikallisella tietokoneella, eikä lähetä mitään verkkoon.
Subtitle Edit -sovelluksen asentaminen
- TUNI Windows -tietokoneille Software Centerissä
- Muille tietokoneille (Windows ja Linux) asennuspaketin voi ladata sivustolta https://github.com/SubtitleEdit/subtitleedit/releases
Tekstitys manuaalisesti
Tekstitys tai litterointi puheentunnistuksella
Valmistautuminen
Henkilötietojen käsittely
- Jos käsittelet henkilötietoja, sinun pitää aina tehdä käsittelystä tietosuojan riskien arviointi, katso ohjeet siihen sivuilta Tutkimuksen tietosuoja – yleisohje ja Tietosuojan vaikutustenarviointi.
- Jos käsittelet erityisiin henkilötietoryhmiin kuuluvia tietoja (EU:n yleisen tietosuoja-asetuksen artikla 9) tai muuta aineistoa, jonka vuotaminen vääriin käsiin voisi johtaa vähäistä suurempaan vahinkoon:
- Käsittelystä pitää tehdä perusteellinen tietosuojan vaikutustenarviointi DPIA, katso ohjeet siihen sivulta Tietosuojan vaikutustenarviointi.
- Jos opiskelijan pitää käsitellä erityisiin henkilötietoryhmiin kuuluvia tietoja, tiedekunnan pitää tehdä opiskelijalle laaja resurssisopimus ja pyytää IT Helpdeskin kautta hänelle käyttöön samanlainen keskitetysti ylläpidetty tietokone kuin henkilökunnallakin.
- Aineistoa saa käsitellä vain tietohallinnon keskitetysti ylläpitämällä tietokoneella, ei koskaan omalla kotitietokoneella.
- Aineisto ja litteraatti pitää tallentaa erillisellä ohjelmalla salattuna. Katso ohjeet sivulta Tutkimusdatan hallinta ja tallennus.
- Puheentunnistus OpenAI Whisper -pohjaisilla algoritmitmeilla toimii kaikilla Windows-tietokoneilla. Se toimii kuitenkin huomattavasti nopeammin, jos koneessa on Nvidian näytönohjain, jossa on riittävästi muistia.
Puheentunnistus
- Avaa tekstitettävä video- tai äänitallenne valitsemalla Video-valikossa Open video file (huomaa video/audio-valinta oikealla alhaalla).
- Lataa ensimmäisellä ajokerralla ohjelman ehdottama lisäosa mpv klikkaamalla nappia Download and use ”mpv” as video player.
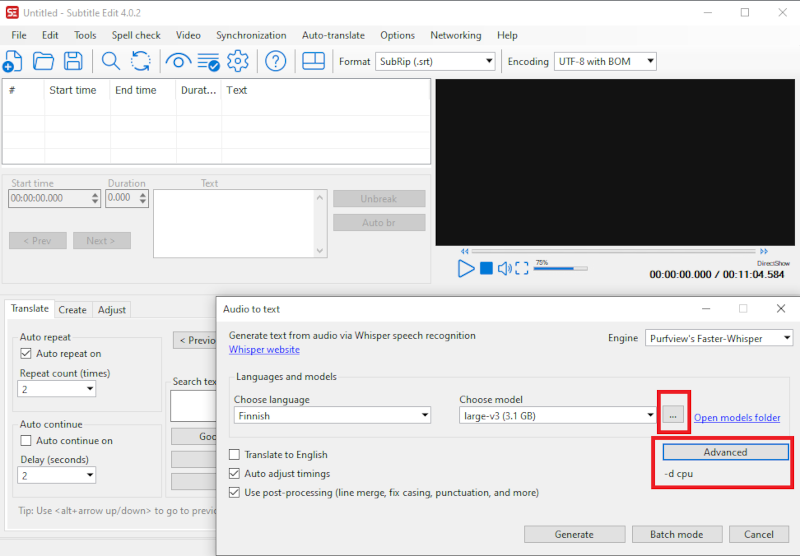
- Valitse Video-valikosta Audio to text (whisper).
- Lataa ensimmäisellä ajokerralla ohjelman ehdottamat lisäosat FFmpeg ja Purfviews Faster-Whisper.
- Anna Engine-kohdassa (puheentunnistusohjelma) olla oletusarvo (tätä kirjoitettaessa Purfview’s Faster-Whisper), koska se on tarkistettu toimivaksi.
- Voit valita käyttöön jonkin toisen enginen, mutta se voi olla tuntematon ohjelma tietoturvamekanismille AppLocker, jolloin AppLocker estää ohjelman suorittamisen ja saat siitä ilmoituksen. Jos niin käy, lähetä it-helpdesk [at] tuni.fi (IT Helpdeskiin) sähköposti, jossa kerrot tietokoneesi nimen ja että käytit Subtitle Edit -ohjelmassa engineä, josta sait AppLocker-ilmoituksen, ja pyydät viestissä, että AppLocker sallii tuon enginen ajamisen. Voit ottaa AppLockerin ilmoituksesta näyttökuvan tai kirjoittaa muuten talteen ilmoituksessa mainittu ohjelma, mutta se tieto löytyy kyllä AppLockerin logeistakin.
- Valitse tallenteessa puhuttu kieli Choose language.
- Valitse Choose model -kohdan kolmen pisteen valikossa kielimalli, jolla haluat tehdä puheentunnistuksen.
- Mallit, joiden nimen lopussa ei lue ”.en”, ovat monikielisiä.
- Mitä isompi kielimalli, sitä paremmin se tunnistaa puhetta, mutta sitä hitaampi se on. Large-v3 tunnistaa ilmeisesti parhaiten. Sillä tunnistus kestää perus-TUNI-tietokoneella noin 3 kertaa tallenteen kestoajan. Medium:lla tunnistus kestää noin puolet siitä, mitä Large-malleilla. Kokeile, mikä malli sopii parhaiten tarpeisiisi.
- Katso lisätietoa malleista Whisper-projektin sivulta.
- Ohjelma lataa käytettävän kielimallin ensimmäisellä ajokerralla ja myöhemmin se löytyy Choose model -listasta. Suurin kielimalli on yli 3 GB ja sen lataaminen kestää aika kauan.
- Lataa ensimmäisellä ajokerralla ohjelman mahdollisesti ehdottamat lisäosat (Cublas, cuDNN libs).
- Valitse Generate käynnistääksesi tallenteen käsittelyn.
- Puheentunnistus voi epäonnistua, jos tietokoneessa on erillinen näytönohjain, jossa on liian vähän muistia (Large-mallit tarvitsevat 8 GB). Määrittele tällöin Advanced-kohdasta lisäasetuksiin "-d cpu" jolloin puheentunnistus tehdään pelkällä prosessorilla. Tuo asetus voi olla hyvä myös tietokoneessa, jossa ei ole erillistä näytönohjainta, koska se voi nopeuttaa tunnistusta.
- Voit laittaa useita tallenteita käsiteltäväksi peräkkäin Batch-toiminnolla.
- Kun tekstitys on tuotettu puheentunnistuksella, voit tehdä editorissa korjauksia tekstityksen SRT-tiedostoon.
- Tallenna teksti valitsemalla File-valikosta Export - Plain text. Samalla voit valita tekstin muotoilua, kuten aikakoodit ja rivitys.
- Katso lisäohjeita ohjelman käyttöön kehittäjän sivulta.
Alla esimerkki, jossa puheentunnistukseen käytetään Large-v3 -kielimallia ja tietokoneen prosessoria.
IT Helpdesk
0294 520 500
it-helpdesk [at] tuni.fi (it-helpdesk[at]tuni[dot]fi)
helpdesk.tuni.fi
Julkaistu: 22.9.2022
Päivitetty: 30.9.2024